Wybór właściwej palety kolorystycznej to nie tylko kwestia estetyki, ale przede wszystkim narzędzie, które może podkreślać kluczowe informacje, porządkować dane oraz ułatwiać zrozumienie skomplikowanych zestawień.
Jednak każdorazowe poświęcanie czasu na dobór kolorów nie dla wszystkich brzmi jak ekscytująca przygoda. Właśnie dlatego warto mieć pod ręką gotowy zestaw palet, który wpiszemy do ustawień naszych narzędzi do wizualizacji. Tylko jak się do tego zabrać?
Rodzaje palet
W wizualizacji danych przyda Ci się kilka rodzajów palet:
- paleta kategorialna (categorical) – w tej palecie używamy różnych kolorów do oznaczenia różnych kategorii, serii lub klas danych. Kluczowe jest to, aby kolory były łatwe do rozróżnienia i przypisania do konkretnej kategorii. Nie możemy mieć wątpliwości, czy dana linia lub słupek na wykresie dotyczy kategorii X, czy może Z, bo kolory są zbyt do siebie podobne. W tej palecie nie układamy kolorów w żadnej kolejności, która sugerowała by jakiś “porządek” (np. od ciepłych do zimnych) – to podejście rezerwujemy dla dwóch kolejnych rodzajów palet.
- paleta dywergencyjna (diverging) – ten rodzaj palet poznamy po tym, że na ich prawym i lewym krańcu mamy dwa różne kolory, np. zieleń i czerwień lub turkus i pomarańcz (reprezentujące jakieś skrajności), a pośrodku kolor neutralny, np. jasnoszary (oznaczający środek skali lub jakiś “punkt krytyczny”). Palety dywergencyjne świetnie sprawdzają się wtedy, gdy chcemy podkreślić odchylenia względem jakiegoś poziomu.
- paleta sekwencyjna (sequential) – może nam się kojarzyć z gradientem 🙂. Zawiera kolejne odcienie danego koloru – od najjaśniejszego do najciemniejszego (lub odwrotnie). Świetnie nadaje się do zobrazowania nasilenia (lub nasycenia) jakiegoś zjawisko – im ciemniejszy odcień, tym czegoś “więcej”.
Oprócz wspomnianych palet, przydadzą nam się też tzw. kolory semantyczne, czyli takie, z którymi wiążemy jakieś konkretne znaczenie, np.: pozytywne (wzrosty), negatywne (spadki), ostrzeżenia itd. Kolorami semantycznymi mogą być także te oznaczające jakichś konkretnych konkurentów (np. Allegro OneBox kojarzymy raczej z butelkową zielenią, a Paczkomaty InPost z miodową żółcią), ale nie zawsze jest to właściwe podejście – warto zważyć, czy rzeczywiście ułatwia to czytanie wykresów.
Czego jeszcze potrzebujemy?
Stworzenie palet jest oczywiście kluczowe, ale przy wizualizacji danych nie możemy też obyć się bez dobrania kolorów dla kilku innych elementów, tj.:
- osi,
- siatki,
- etykiet,
- tytułów,
- opisów,
- adnotacji.
Pierwsze pięć elementów powinno być możliwie “subtelnych”, bo będą stanowić tło dla naszych danych i nie powinny odciągać od nich uwagi. Z kolei w przypadku adnotacji możemy trochę bardziej poszaleć, bo przecież mają przykuć wzrok to jakiegoś konkretnego miejsca na wykresie 🙂.
Od czego zacząć?
No dobrze, wiemy już, czego potrzebujemy, ale jak się do tego zabrać?
Jeśli mamy już jakiś system identyfikacji wizualnej, możemy zainspirować się naszymi “firmowymi” kolorami. Nie zawsze jednak się to sprawdzi – czasami są one np. na tyle jasne, że użycie ich na wizualizacjach zaszkodzi czytelności. Wtedy nie bójmy się skorzystać z lekko zmodyfikowanej wersji koloru.
Na przykład: na mojej stronie internetowej korzystam z kilku podstawowych kolorów, oznaczonych kolejno w numeracji HEX jako: #6dd3e8, #00b9e8, #304ea1 i #0092b7.
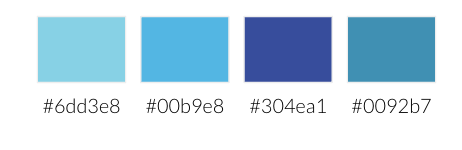
Pod kątem czytelności najlepszymi kandydatami na mój “główny” kolor dla wizualizacji byłyby dwa ostatnie:
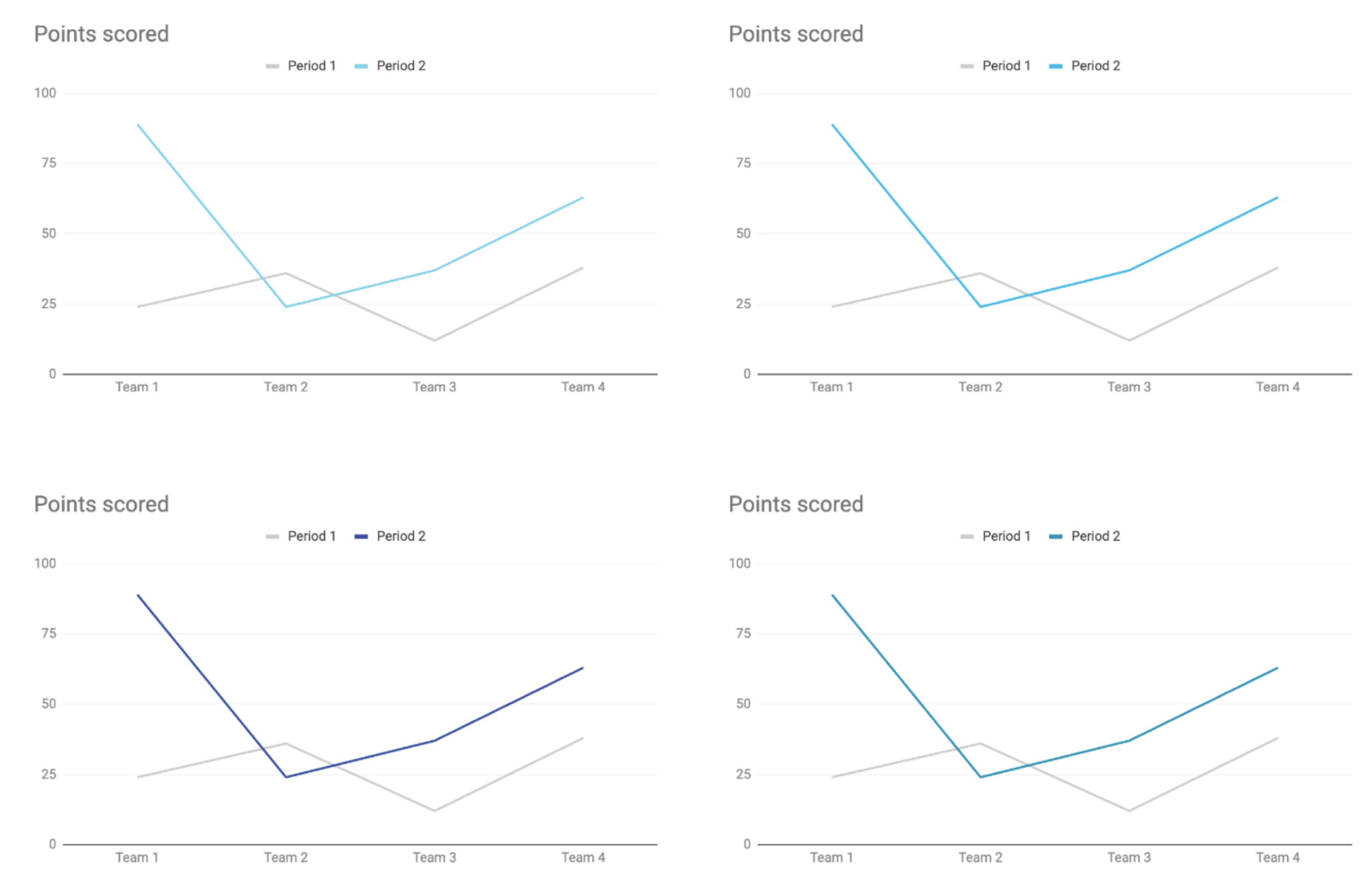 Bliżej mi do ostatniego, jest też bliższy dominującej kolorystyce moich materiałów, więc wybieram #0092b7 (tzw. Bondi Blue).
Bliżej mi do ostatniego, jest też bliższy dominującej kolorystyce moich materiałów, więc wybieram #0092b7 (tzw. Bondi Blue).
Paleta kategorialna
Na jego podstawie mogę zacząć dobierać kolejne kolory do moich palet. Inspiracją mogą służyć gotowe narzędzia, np.: Adobe Colours, Coolors, Data Color Picker, a nawet Canva. O pomoc możemy poprosić też oczywiście Chat-GPT, które zaproponowało mi taki pomysł na paletę kategorialną (prompt: “Generate an 8 color categorical palette for data visualization including #0092b7”, przy czym efekty mogą być różne przy kolejnym wywołaniu):
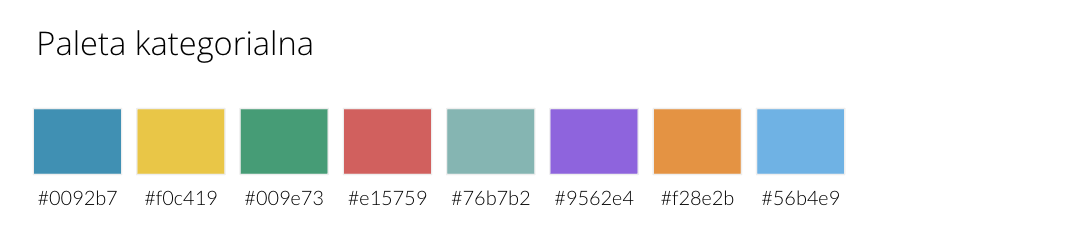
Niezłe, biorę! Oczywiście mogłam też poprosić o większą liczbę kolorów, ale uwierz – wykres z ponad 8-ma kolorami to naprawdę nienajlepszy pomysł!
Z kolei Adobe zaproponowało mi taki zestaw (też fajny 🙂, zwłaszcza ta oberżyna!):
 Zostanę jednak przy propozycji Chat-GPT.
Zostanę jednak przy propozycji Chat-GPT.
Warto też przygotować sobie zestaw jaśniejszych odcieni tych kolorów – przydadzą się np. do porównań (np. rok do roku) lub prezentowania wartości predykcyjnych (prognozowanych). Ja załatwiłam to z pomocą narzędzia Image Color Picker, wrzucając po kolei kody kolorów i wybierając z opcji tints wersję 60%.
Efekt końcowy to:

Paleta dywergencyjna
Czas na drugi rodzaj palety. Przygotowałam sobie dwie (druga z myślą o osobach z problemami z widzeniem kolorów, dla których czerwień i zieleń nie jest tak łatwa do odróżnienia), bazując na kolorach z kategorialnej i wrzucając je do Data Color Picker. Oto rezultaty:

Palety sekwencyjne
Ostatni rodzaj palet stworzyłam ponownie z użyciem Data Color Picker. Efekty są całkiem fajne:

Nieźle poszło, nie? To lecimy dalej!
Szarości
Do naszych wizualizacji będziemy potrzebować też palety neutralnych kolorów, na tle których lepiej wyeksponujemy to, co istotne. W tej roli najlepiej sprawdzą się szarości.
Co ciekawe, szarość szarości nierówna (pozdrawiam ekipę, która malowała ściany w moim mieszkaniu z rozpiską, która farba jest przeznaczona do konkretnego pokoju 🙂)! Jeśli chcemy bardzo zadbać o estetykę, możemy wybrać wariant szarości, który jest najbliższy dominującej kolorystyce naszych dokumentów, czy dashboardów. Ponieważ u mnie są to wspomniane błękity, poprosiłam ChatGPT o paletę “blue-ish greys”. Oto efekt:
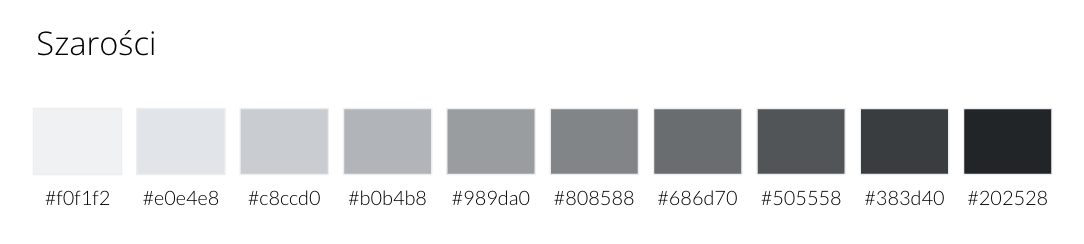 Jeśli masz wątpliwości, jakiego rodzaju szarości użyć, najlepszym wyborem będzie stworzenie palety na bazie “zwykłej” szarości, czyli #808080.
Jeśli masz wątpliwości, jakiego rodzaju szarości użyć, najlepszym wyborem będzie stworzenie palety na bazie “zwykłej” szarości, czyli #808080.
Więcej o szarościach w wizualizacji danych znajdziesz we wspaniałym poście Data Rocks, którym mocno inspirowałam się przy pracy nad tym materiałem.
Elementy wykresu
OK, mamy już prawie wszystko, ale zostały nam jeszcze podstawowe elementy wykresu. Przy doborze ich kolorystyki powinniśmy kierować się tym, aby nie “przyćmiły” prezentowanych danych, jednocześnie pozostając czytelnymi.
W dużej mierze możemy tu bazować na wygenerowanej wcześniej palecie szarości. Ja zdecydowałam się na taki dobór:
- osie: #505558
- opisy osi: #505558
- siatka: #f0f1f2
- tytuły: #383d40
- podtytuły: #505558
Tak prezentuje się przykładowy wykres z użyciem tych kolorów:
Całkiem fajny, prawda?
Kolory semantyczne
Na koniec pora na kolory semantyczne, czyli takie, z którymi wiążemy jakieś konkretne znaczenie. Skupmy się na trzech najczęściej potrzebnych: pozytywnym, negatywnym i ostrzeżeniu.
W środowisku specjalistów od wizualizacji danych nie ma konsensusu co do tego, czy stosować w tym wypadku zieleń i czerwień – jest przecież całkiem niemała grupa osób, która ma problemy z rozróżnieniem tych dwóch kolorów. Jednocześnie to one najbardziej kojarzą się w naszej kulturze odpowiednio z czymś dobrym i złym (uwarunkowania kulturowe to osobny, złożony temat!). Jedno jest pewne – jeśli zdecydujemy się na taki dobór kolorów semantycznych, nie powinny one stanowić jedynego oznaczenia – zasygnalizujmy dodatkowo spadki i wzrosty np. za pomocą strzałek.
Ja wybrałam kolory semantyczne na podstawie wcześniej wygenerowanej palety, czyli:
- pozytywny: zieleń #009e73
- negatywny: czerwień #e15759
- ostrzeżenie: żółć #f0c419

Można jednak rozważyć, czy w takim wypadku nie powinnam usunąć ich z palety kategorialnej, żeby nie miały “podwójnego znaczenia”.
Efekt końcowy
OK, mamy to! Tak wygląda mój zestaw palet kolorystycznych do wizualizacji danych. Jak się podoba?
Pora wpisać je do ustawień domyślnych Excela, Google Spreadsheet, PowerPoint, czy Looker Studio 🙂
Warto doczytać:
https://buttondown.email/datarocksnz/archive/design-matters-6-the-ultimate-dashboard-colour
https://buttondown.email/datarocksnz/archive/design-matters-7-ultimate-dashboard-palette-practice
Fajne? Przydatne? Udostępnij dalej! Możesz też postawić mi wirtualną kawę 🙂
